 FACT CHECKED
FACT CHECKED
Data mining algorithms are computational tools designed to extract patterns from data, optimize model parameters, and apply those models to data-driven tasks.
As big data expands, the need to refine these algorithms has grown. Businesses now face the challenge of working with large, unstructured datasets often fragmented across different systems—known as data silos.

These silos make it difficult to extract useful information efficiently, which in turn drives innovation in data mining and segmentation techniques to help organizations capture new value from insights.
Data mining algorithms provide methods to overcome these challenges, enabling more accurate predictions and better understanding of complex datasets. Below, we will explore data mining and its practical uses and review fifteen specific algorithms.
What are the different types of data mining techniques?
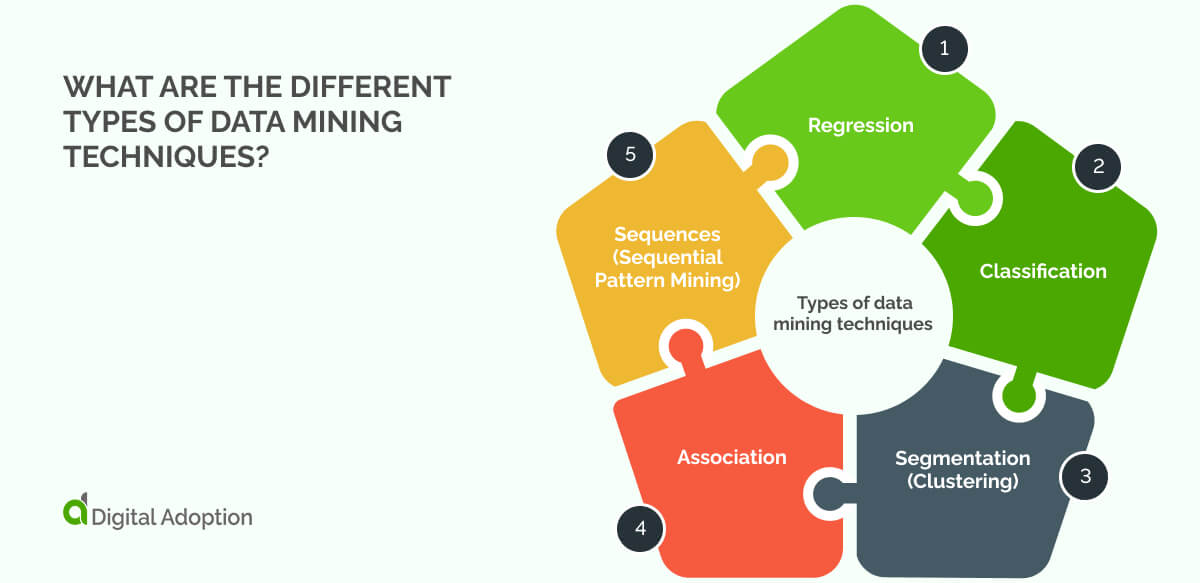
Data mining algorithms leverage various kinds of techniques, each serving distinct purposes.
Regression algorithms analyze relationships between variables, facilitating predictive modeling, whereas segmentation algorithms partition data into segments, aiding in the analysis of unlabeled datasets.
The fifteen algorithms discussed in this article fall into one of the following five categories:
- Regression: Regression algorithms are useful for predictive purposes. They attempt to establish a relationship between a dependent and independent variable and then make forecasts based on that relationship.
- Classification: Classification algorithms categorize data into several classes, which are then assigned labels. They do this by examining the dataset as it is received and classifying new inputs based on these classifications.
- Segmentation (Clustering): Segmentation algorithms separate data into regions. These are useful for unlabeled data that don’t have categories. These algorithms are closely related to clustering algorithms; some use the two terms interchangeably.
- Association: Association algorithms attempt to discover how items are related to one another. They do this by looking for rules that govern the relationships between variables in databases.
- Sequences (Sequential Pattern Mining): Sequences analysis imposes order on observations that must be preserved when training models. In many other algorithms, the sequence is not important, but the order is important with sequence analysis. Experienced data miners will use more than one algorithm to achieve the most useful model for their data strategy.
Experienced data miners will use more than one algorithm to achieve the model that is most useful for their data strategy.
Top 15 data mining algorithms snapshot
The algorithms in this list can be categorized into statistical-based and data-driven.
Statistical-based algorithms, such as regression, model relationships using statistical methods. Data-driven algorithms, like clustering, extract patterns directly from the data.
Below is a snapshot of 15 widely used data mining algorithms grouped by these functions.
| Algorithm | Model Type | Description |
| C4.5 | Statistical-based | Builds decision trees using information gain for classification. |
| Naive Bayes Algorithm | Statistical-based | A probabilistic classifier based on Bayes’ theorem with strong independence assumptions. |
| Logistic Regression | Statistical-based | Predicts binary outcomes using a logistic function and statistical modeling. |
| Linear Discriminant Analysis | Statistical-based | Finds linear combinations of features to separate classes. |
| Generalized Linear Models | Statistical-based | Extends linear models to handle non-normally distributed data. |
| Support Vector Machine (SVM) | Statistical-based | Finds optimal hyperplanes to separate data points for classification/regression. |
| Anomaly Detection | Statistical-based/Data-based | Identifies unusual data points that deviate significantly from the norm. |
| Expectation-Maximization (EM) | Statistical-based | Iteratively estimates parameters of statistical models with latent variables. |
| Random Forest | Data-based | Ensemble of decision trees for classification or regression, reducing overfitting. |
| K-Means Clustering | Data-based | Partitions data into k clusters based on minimizing within-cluster variance. |
| Clustering | Data-based | A general term that groups similar data points. |
| Orthogonal Partitioning Clustering | Data-based | Clusters data by recursively partitioning feature space along orthogonal axes. |
| Sequence Clustering | Data-based | Groups sequences of data based on similarity patterns. |
| Apriori | Data-based | Finds frequent itemsets in transactional data for association rule learning. |
| Isolated Forest Algorithm | Data-based | Efficient anomaly detection by isolating anomalies in random partitions. |
15 Examples of data mining algorithms
Now that we’ve explored data mining algorithms and their different types, let’s examine fifteen notable algorithms data scientists are leveraging today.
1. C4.5
C4.5 is a decision tree algorithm used for classification and prediction. It builds a tree-like structure by evaluating data and splitting it based on attribute values. Each node represents a decision based on a specific attribute, and the branches determine the outcomes.
C4.5 improves upon its predecessor, ID3, by handling continuous data and pruning branches to avoid overfitting. C4.5 is a statistical-based algorithm used for classification tasks. A practical example involves classifying customer activity data, where the algorithm splits into attributes like age, income, or purchase history to predict future buying behavior.
2. Expectation-Maximization
Expectation-maximization is a clustering algorithm.
Clustering algorithms, as the name suggests, find patterns based on how data is “clustered” according to certain attributes—that is, they segregate data based on individual groups. When looking at a graph, we can easily see data points clustered closely together.
This algorithm consists of two steps. First, it attempts to calculate the probability of a data point belonging to a cluster and then updates the model parameters. These steps are repeated continuously until a closer distribution equalizes.
3. Naïve Bayes Algorithm
Naive Bayes algorithms are effective for data exploration and predictions. They are statistical algorithms that rely on statistical principles, particularly Bayes’ Theorem, to make predictions. These algorithms assume that the features used to classify data are independent, simplifying the model-building process.
In data mining, Naive Bayes is commonly applied for classification tasks, such as aiding customer discovery, determining customer behavior, or categorizing emails as spam. The algorithm calculates the probability of an outcome based on prior knowledge of the data, making it lightweight and fast. While initially simple, it can be refined using other algorithms for more precise predictions.
4. Support Vector Machines
A Support Vector Machine (SVM) is a classification algorithm that maximizes the margin between different classes in an N-dimensional space.
It identifies a hyperplane that separates data points of different categories with the greatest distance. SVM works by finding the support vectors, which are the data points closest to the hyperplane, ensuring accurate classification. For non-linear data, SVM uses kernel functions to map data into higher dimensions, making it possible to find a separating hyperplane.
This technique is widely used for classification tasks, especially when the data is complex and involves multiple features. SVM is a data-based algorithm because it builds its model directly from the dataset and adapts to its structure for classification.
5. Sequence Clustering
Sequence clustering is a combination of sequence analysis and clustering. The algorithm identifies distinct sequences from the data and then groups them based on their patterns and order. It evaluates the similarity between sequences to form clusters that represent common behaviors or events. This simplifies complex sequential data, revealing latent structures within the dataset.
Sequence clustering is a data-based algorithm that effectively mines insights from ordered data by uncovering trends hidden within the sequences. This produces concrete information for scenarios like market analysis and time-series forecasting.
Sequence clustering is a data-based algorithm that directly processes and groups raw data to explore patterns and insights.
6. Clustering
By itself, clustering algorithms focus on clusters of cases with similar attributes. The Expectation-Maximization algorithm and the sequence clustering algorithm above are examples of clustering algorithms.
These algorithms organize data points into groups based on shared characteristics with no prior labels or classifications. They identify patterns within the data and form clusters to make analysis more manageable.
For instance, the Expectation-Maximization algorithm assigns data to clusters iteratively, refining groupings for accuracy. Clustering is a data-based algorithm, as it relies on the inherent structure of the raw data to identify clusters without predefined categories. This approach has become increasingly powerful with the rise of big data adoption.
7. Orthogonal Partitioning Clustering (OPC)
Orthogonal Partitioning Clustering (OPC) is a partitioning algorithm that divides data into distinct clusters by maximizing their separation. OPC is a data-based algorithm that relies on raw data to identify and define clusters without needing labeled data.
The algorithm works by assigning centroids to each cluster and then adjusting the cluster assignments through iterative optimization.
It aims to minimize the distance between data points within a cluster while maximizing the distance between different clusters. For example, OPC is used in image segmentation, which groups pixels based on similar characteristics such as color or texture. As these techniques grow more common, especially in sensitive applications, they must be guided by strong data ethics to ensure fairness, privacy, and responsible use.
8. Random Forest
Random Forest is an ensemble algorithm that builds multiple decision trees from random subsets of data. Each tree is trained with different data samples and random features for splitting. The algorithm combines the output of all trees to make a final prediction, using majority voting for classification or averaging for regression.
Random Forest can classify customers based on age, income, and spending patterns in customer segmentation. It’s effective with high-dimensional data and can handle missing values. As a data-based algorithm, it relies on learning directly from data without assumptions about the structure.
With increased data use, especially in personal and financial contexts. Random Forest models must be developed with safeguards to protect sensitive information and comply with privacy regulations.
9. K-Means Clustering
This is a clustering algorithm that views items as points in space. The K-means algorithm defines a center point for each cluster and gradually regroups clusters closer to those centers. After completion, clusters that may have consisted of noisy data are separated into groups based on similarities.
K-means is widely used for customer segmentation, grouping customers by purchasing behavior, demographics, or preferences. It’s effective for large datasets and works best when the number of clusters is known beforehand.
Data transformation is key in improving the effectiveness of clustering algorithms like K-means. It involves converting raw data into a more usable format, such as normalizing or scaling features, to ensure accurate and meaningful cluster formation. Proper transformation helps reduce bias and enhances the clustering process, particularly with diverse or unevenly distributed datasets.
10. Apriori
This is an unsupervised algorithm that looks for association rules in large datasets. Unsurprisingly, this is an example of an association algorithm.
The Apriori algorithm performs three essential tasks, including joining items, pruning that set, and repeating these steps until it completes the rule generation. It identifies frequent itemsets in transaction data and derives association rules based on support and confidence levels.
Apriori is often used in market basket analysis, which uncovers relationships between frequently bought products. For example, it might reveal that customers buying bread usually purchase butter, helping businesses improve product placement and promotions.
11. Logistic regression
Logistic regression is a statistical method used for binary classification problems. It models the probability of a binary outcome by fitting data to a logistic curve. The algorithm calculates the relationship between independent variables and the likelihood of a certain class, producing outputs between 0 and 1.
In data mining, logistic regression is used to predict customer churn. It might estimate the likelihood that a customer will cancel a service based on usage patterns and demographic factors. The algorithm’s simplicity and efficiency make predicting probabilities in large datasets with multiple variables effective.
Data lifecycle management is critical in ensuring data quality used in logistic regression models. From the initial data collection to model training and ongoing monitoring, managing each phase ensures that the data remains relevant and accurate. Proper versioning and tracking of data allow models to be retrained with updated datasets, maintaining their predictive power and compliance with evolving data regulations.
12. Isolated forest
The Isolated Forest algorithm detects anomalies in large datasets by randomly selecting features and splitting the data into smaller parts. Anomalies are easier to isolate, requiring fewer splits than normal data.
The algorithm builds decision trees, identifying outliers based on how quickly they are isolated. It operates without relying on statistical assumptions about the data distribution. An example application is identifying defective parts in a manufacturing process.
The algorithm isolates rare, outlier data points, such as faulty items from sensor readings, and flags them for inspection. Isolated Forest is fast, effective for large datasets, and can outperform other methods in speed and scalability.
13. Linear discriminate analysis (LDA)
Linear Discriminant Analysis (LDA) is a supervised algorithm that classifies data by finding a linear combination of features that best separates different classes. It works by maximizing the variance between classes while minimizing the variance within each class.
LDA is particularly useful when data is high-dimensional, as it reduces the feature space to the most relevant components. This algorithm can be leveraged to detect spam across emails. It helps classify emails as spam or not by assessing patterns in text and sender attributes.
LDA processes these features to determine the likelihood that an email belongs to a specific category, improving accuracy in identifying spam. Another example includes predicting customer churn, where LDA helps separate high-risk customers from low-risk ones based on behavioral data and demographic attributes
14. Anomaly detection (AD)
Anomaly Detection (AD) is an algorithmic technique used to identify patterns in data that do not conform to expected behavior. It looks for rare events that stand out from the rest. Anomaly detection can be leveraged for a wide range of applications, from monitoring the health of IT systems to identifying fraud in FinTech.
In AI, AD helps detect unexpected behavior in models, such as when predictions deviate from established patterns, suggesting the model might be underperforming or needs retraining. It’s often used to detect shifts in user preferences, where sudden changes may indicate evolving trends or issues with data consistency.
AD operates without needing labeled data, making it flexible for dynamic environments where patterns are constantly changing.
15. Generalized linear models (GLMs)
Generalized Linear Models (GLMs) are statistical models that predict outcomes based on multiple variables. They extend traditional linear regression to handle different types of data, like binary outcomes or counts.
In IT, GLMs can help predict system performance, such as server failures, by analyzing load, traffic, and error rates. They can also use historical patterns to identify when a system will likely crash under a heavy load.
GLMs can also model response times, identifying pain points and factors that cause delays. These models offer flexibility in handling diverse data types, making them useful for more nuanced IT predictions.
Ensuring data integrity in the digital age
Data is arguably one of the most valuable forms of currency in the digital transformation era.
The demand and reliance on big data will continue to grow as businesses expand their use of AI and machine learning to interpret user behavior. Enterprises must consider how data is gathered, labeled, and validated to preserve accuracy and reduce AI risk across the pipeline.
Machine learning models are only as reliable as the data they learn from. Incomplete, unbalanced, or historically biased datasets can embed prejudice into algorithms. If left unchecked, AI bias can result in systems that exclude or misclassify certain groups.
Data privacy and protection are just as important. Organizations risk exposing sensitive user data or violating compliance rules without clear protective parameters.
As AI adoption expands, privacy concerns must be addressed upfront—otherwise, data mining efforts may produce more harm than insight.
People Also Ask
-
How are classification and clustering different?Classification sorts data into known categories, such as tagging emails as spam or not. The system already knows what the categories are. Clustering doesn’t. It looks for patterns and groups data based on similarities, even if no labels exist.
-
Is one algorithm better than the rest?No single algorithm works best for all use cases. Some work only with labeled data, while others find structure in unlabeled data. For example, neural networks may outperform traditional models in voice recognition but not in structured database queries.
-
Are all data mining algorithms based on AI?No. Many are statistical, like linear regression or k-means. AI-based ones, like deep learning, are used when the data is large, unstructured, or complex. The choice depends on context, accuracy, and speed.


")


